Projects
Current CEADS research
Cybersecurity of machine learning systems
The CEADS team has prototyped three attack surfaces: 1) inference attacks to “steal” or replicate the machine learning model with varying levels of information, 2) trojan attacks to infiltrate and falsify machine learning systems with “look-a-like” systems that have triggers for certain malicious behavior, and 3) adversarial reprogramming to minimally alter inputs that then trick machine learning systems into targeted misclassification. We found that autonomous systems are significantly vulnerable to these attacks.
Inference attacks
In recent years, interest and research in the use of machine learning (ML) systems in nuclear reactors has increased dramatically. Recent advances in computing power have allowed ML algorithms to become faster and more adept at diagnosing anomalies, or transients, in the reactor and recommending solutions. As in every area of technology, however, ML systems are vulnerable to adversarial attacks, that is, attempts to subvert the ML algorithm. In order to perform an adversarial attack, the ML model, which is usually kept secret, is needed. However, given a set of inputs representative of the original training dataset and predictions from the model on these inputs, it is possible to train a model that behaves almost exactly like the original. This sort of attack is called Model Inference, or Model Stealing. In this report, the model being copied is
called the victim model.
The attack the assailant uses is dependent on the availability of the model. In a white box attack, the attacker has complete knowledge of the model parameters, inputs, and outputs. Gray box attacks assume some level of knowledge of the victim model along with the inputs and outputs, such as whether the model is a neural network or a k-Nearest Neighbors classifier. In black-box attacks, the attacker only has access to the inputs and outputs. Black box attacks also seem like they would have the most applicability since it is easier to gain access to a model’s inputs and outputs than the model itself.
Machine learning algorithms similar to the ones in this project are being investigated for use in nuclear reactor systems, which is concerning because all of them aside from the neural networks proved very easy to replicate. Because even simple neural networks often have thousands of different parameters, they are harder for something like H2O or even AutoKeras to copy. Algorithms such as a k-Nearest Neighbors classifier or a decision tree are easy to copy with near near perfect accuracy because they are composed of just a few parameters.
Trojan attacks
The goal of a Trojan attack is to alter a model and have the changes unrecognizable to the users. The trojaned model still performs well on the original data even though some weights have been altered, yet the trojaned model is sensitive to “masks” or “triggers” and when they are present in the data the model will misclassify the state. This could lead to several dangers especially in a nuclear power plant. An attacker could make a machine learning algorithm for the reactor misclassify data that is originally a transient as a steady state operation when the trigger is found. The attacker could do the opposite also making a steady state operation classify as a transient when the pattern is found.
![]()

The results of this attack on classifying masked data as transients, can be seen in Table 18. This table demonstrates the success of the attack after retraining on the mixed dataset. The trojaned model performs with high accuracy on the original data (NM) as well as high on the masked test set (M) when classifying masked data as transients. The model was then retrained to classify masked data as steady state operations. The results of this attack are show in Table 19, which indicates similar success.
![]()

Adversarial reprogramming
Adversarial reprogramming alters “background” or “non-robust” features in the data, utilized by machine learning models, to trick these models into misclassification. Robust features are features that we (humans) are able to see and use to inform our decisions, whereas non-robust features are patterns that are indistinguishable to humans but are nearly always used by machine learning models to help with their classification. The reason they are problematic is because an image can be edited in a way to change the non-robust features - and thus confuse the model - without it being a noticeable change to a human, and all with minimal change to the inputs.

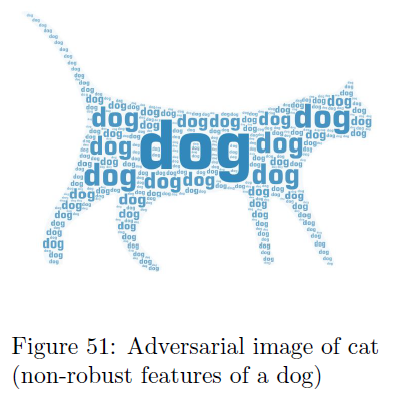
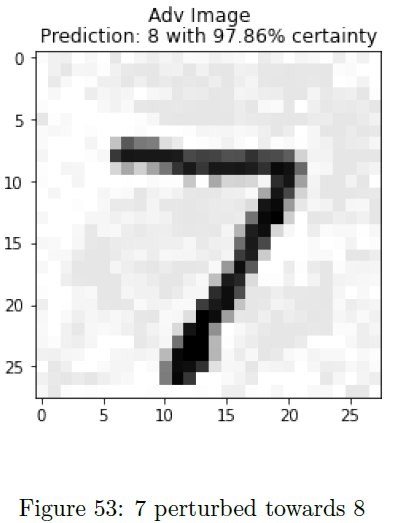
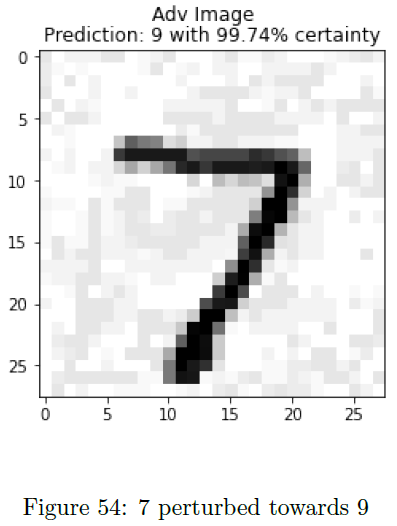
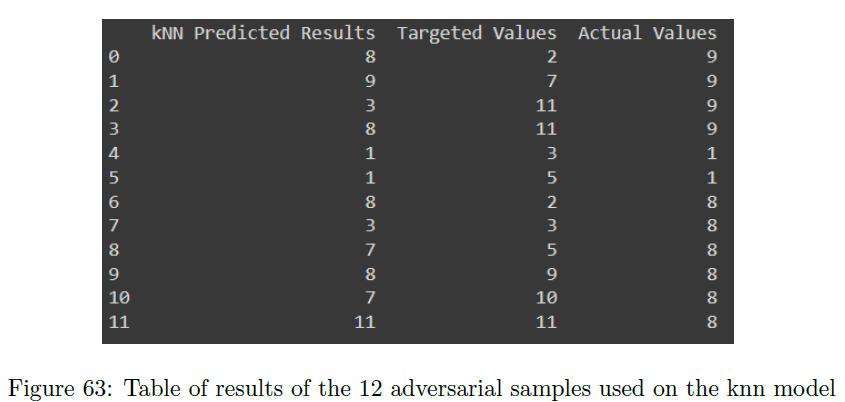
This attack utilized the Fast Gradient Sign Method (FGSM) to train the adversarial images, with a unique twist: it utilized an iterative FGSM algorithm. To test if other machine learning models were vulnerable to this attack, besides neural network image classifiers, adversarial inputs were created and tested on a kNN (k-nearest neighbors) classifier used in predicting various states of a nuclear power plant (normal and transient behaviors). Figure 63 summarizes the results, showing the model’s prediction on the adversarial sample, the target the adversary was trying to perturb towards, and the actual class value. Of the 12 different samples, 7 of the 12 were fooled from the original label; however, only 2 of those 7 were tricked towards the correct target. Overall, while not perfect at tricking the model, this is effective to show how it is possible to disrupt a k-NN model with minimal change to the input.
Utilizing machine-learning-accelerated models in quantum chemistry
Hydrogen is an important energy carrier resource in response to limiting greenhouse gas emissions. Solid oxide electrolysis cells, including proton-conducting and oxygen-conducting electrolyzers, are highly efficient carbon-neutral hydrogen technologies. The features central to their systems are a multitude of multiphase interactions at interfaces, which in turn influence driving forces for both desired and undesired reactions. The complexity of multiphase interactions provides numerous grand challenges in terms of understanding the detailed properties for performance improvement and materials development. Therefore, new approaches are essential to improving mechanistic understanding and predictive capability for optimization. The purpose of this project is to develop a robust predictive framework to understand multiphase interactions at solid/gas and solid/solid interfaces by coupling machine learning (ML) and quantum chemistry. The deep understanding will accelerate material screening for electrode and electrolyte and components optimization in solid oxide electrolysis cells. Metaheuristic algorithms employed in ML mitigate the concerns about the accuracy of ML predictions in materials science due to the predicament of scarce data sets. In addition, the predictive framework goes beyond common composition/structure-property-behavior relationship identification. Its transferability between systems and processes will facilitate the development of more efficient systems for energy storage, transport, and conversion.
Machine learning models for prediction of pebble bed reactor run-in
The run-in process requires bringing a high temperature gas-cooled pebble bed reactor (PBR) from fresh lower enriched fuel mixed with graphite pebbles to an equilibrium core with higher enriched fuel which is recycled for multiple passes through the core. To achieve an equilibrium core, the run-in process can be adjusted to ensure high fuel utilization of low enriched fuel, rapid approach to full power, or some combination of these. This requires constant tuning during the run-in for reactor variables such as the reactor power, fuel pebble enrichment, fraction of graphite pebbles, fuel flow rate, helium inlet temperatures, and control rod positions, which is currently done manually to assess the viability of the run-in. The goal of this project is to create machine learning models which accurately predict the run-in process given a set of design parameters.
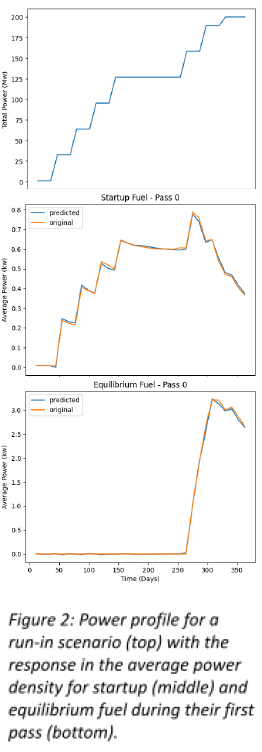
Our work has shown that using a recurrent neural network (RNN) can provide a model that can accurately capture many of the features important to the first 365 days of a run-in problem. Figure 2 provides an example of how a RNN using three time-dependent input variables can capture the average power density for both startup and equilibrium fuel, even when equilibrium fuel is not initially present in the core. Preliminary work found that splitting the output variables into three major categories (i.e. k-eff, average power, and burnup) allowed for the creation of three RNNs with a mean absolute error around 0.01. This work provided a proof of concept and given the level of accuracy achieved with an unrefined RNN, there are many advantages to be gained by delving deeper into the creation of ML models for the PBR run-in scenario.
Advanced Test Reactor (ATR) fuel loading optimization with machine learning
Optimizing the fuel loading in a reactor is an important step in reducing economic costs while maintaining safety standards. Despite being well-studied for light water reactors (LWRs), fuel load optimization has had limited application to research reactors and had never been applied to the Advanced Test Reactor (ATR). The ATR is a complex research reactor and cannot benefit from symmetry due to significant power tilts in the reactor and the fact that some experimental insertions into the reactor could add or remove reactivity. Preliminary research used clustering and k-nearest neighbors to achieve two slightly different fuel loadings that were then run in the MC21 Monte Carlo code. The original fuel loading used 19 fresh fuel elements. The first simulated fuel loading used 16 fresh fuel elements and 524 fewer grams (g) 235U. The second simulated fuel loading used 17 fresh fuel elements and 303 fewer grams 235U. An iterative process was completed for the shim rotations for the first simulated fuel loading and the fuel loading was deemed viable.
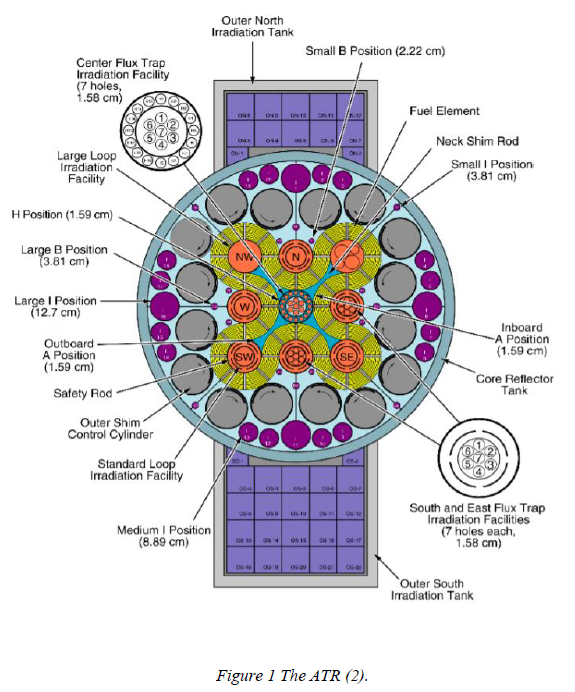
The end goal is to optimize the fuel loading to require fewer fresh fuel elements, thus reducing costs to the ATR. To use a more sophisticated machine learning model, such as neural networks, a significant amount of data simulation will need to be completed. A methodology must be established to determine the correct shim positions to optimize the fuel loading. Ultimately, the goal is to create a tool that runs quickly enough to be useful to analysts which can be used in conjunction with engineering judgement to create a safe, optimized fuel loading.
Past CEADS research
Utilizing ML and AI to predict battery performance
- More information coming soon
Utilizing machine learning to recognize nuclear reactor transients
- More information coming soon
And more:
- Novel methods for data storage and transfer within computational and multiphysics codes
- Database methods for nuclear materials
- Modernization of and development of APIs for legacy codes
- Multiphysics coupling drivers and APIs